About ten days ago my network connection with Virgin Media started to play up. I was experiencing significant packet loss, at times in excess of 50%, and increased latency times with peaks at more than 100ms.
Many other users have been reporting similar issues (see e.g. 🔗 VM Community Forum). On various forums it has been suggested that a recent VM Hub 3 firmware update is to blame. However, my firmware has not changed since I signed up with VM and is at version 9.1.1811.401.
Another suggestion was to use the Hub 3 in modem mode. My Hub 3 has been in modem mode right from the start with an OPNsense router / firewall doing the heavy lifting.
The only recent changes in my side of the setup was a minor OPNsense upgrade and the activation of the Postfix service on the OPNsense router. None of these changes should have caused the problems I have been experiencing.
I then came across a couple of threads (see 🔗 and 🔗) suggesting that DNS lookups initiated by the Unbound DNS service running on the OPNsense router interact with the Hub 3 and/o r the Virgin Media network resulting in the modem becoming less and less responsive.
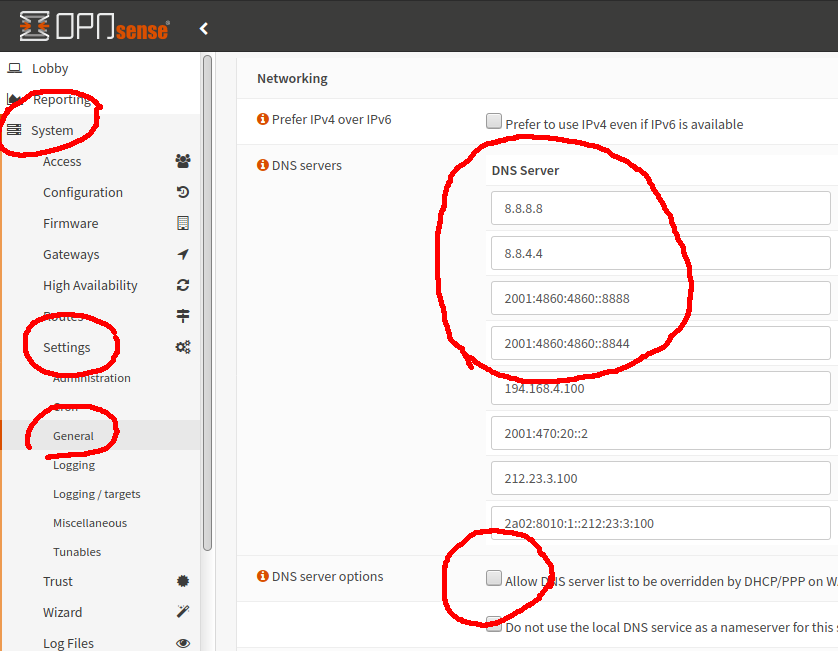
To fix, or at least mitigate the problem, we have to change the Unbound DNS server configuration to switch from ‘resolver’ to ‘forwarder’ mode:
First make sure that your system wide DNS servers are not defined to be on the Virgin Media network. I use Google DNS servers, you may prefer Cloudfare, in which case enter
- 1.1.1.1
- 1.0.0.1
- 2606:4700:4700::1111
- 2606:4700:4700::1001
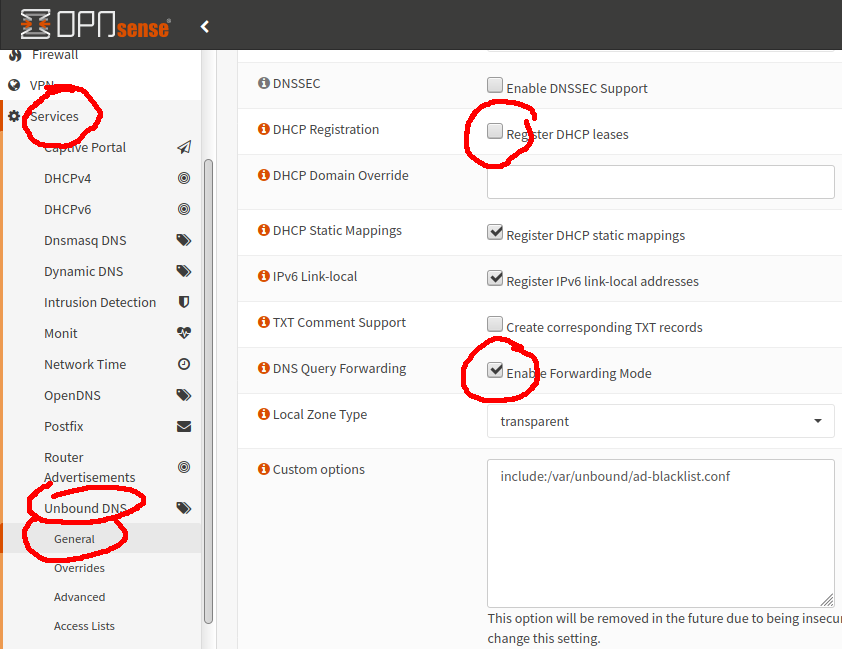
Enable forwarding mode:
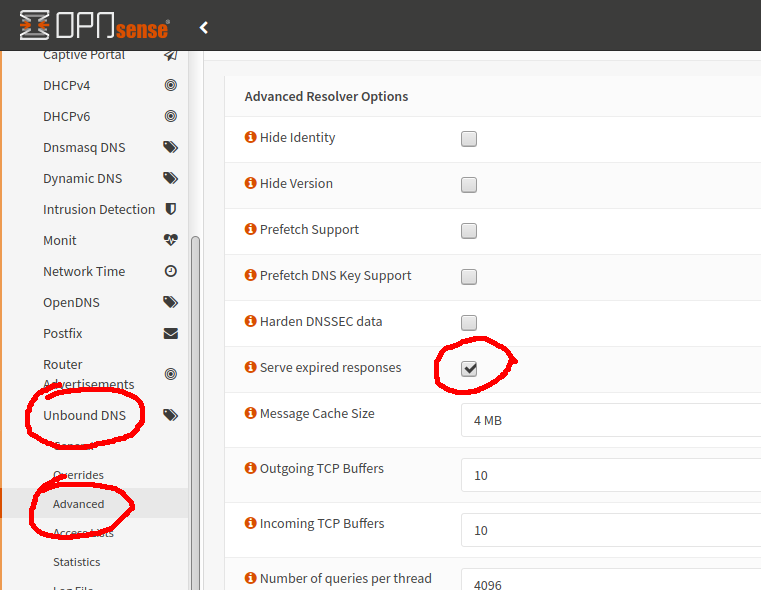
Further reduce latency by serving still probably valid although expired addresses:
Once these changes are applied, DNS traffic should be significantly reduced to a level which the Hub 3 can now cope with – hopefully. The Hub 3 should, in principle, clear its buffers/queues or whatever else is causing the logjam and the at which packets are dropped should fall to zero. This, however, does not seem to happen and the shortcut is to restart the Hub 3.
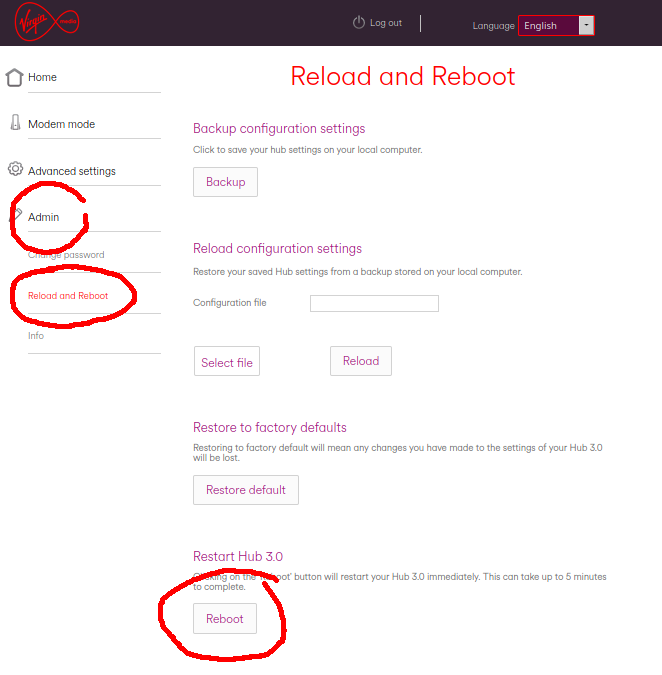
N.B. when I restarted the Hub 3 by power cycling, it got into a bind again, so I recommend rebooting from the admin GUI:
Finally, the happy result showing the transition from bad to OK at around 2:30:
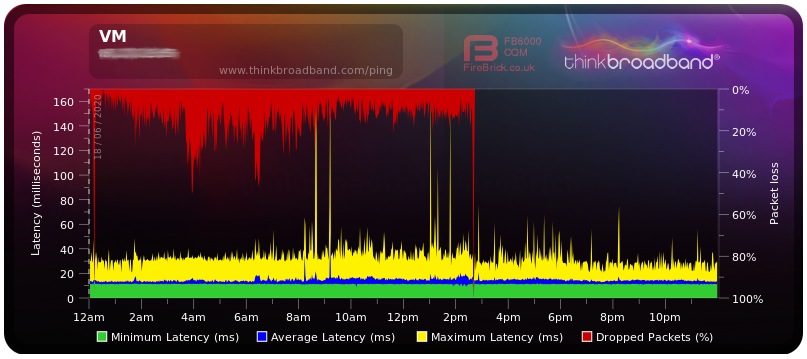
Why does changing the router DNS configuration appear to fix this problem?
There have been well documented problems with cable modems based on the Intel Puma 5 and Puma 6 chipsets:
- 🔗 The Register on the Intel Puma 6 chipset
- 🔗 Puma 6 do not buy list from Approved Modem List
- 🔗 Another article from The Register
- 🔗 DSLreports forum thread on the Puma 6 problem
- 🔗 US class action details
- 🔗 DSLreports Puma 6 test
What is interesting is that this problem has been around since 2016 and neither Intel, nor any of the modem manufacturers bothered to provide a firmware fix. Even worse, ISPs – including Virgin Media – are still knowingly shipping defective modems to customers.
In any case, my limited understanding of the problem is that the Intel chipsets do not have sufficient resources to deal with bursts of small packets. This causes a stall in the packet processing and ultimately results in increased latency and eventually in dropped packets.
At first this was noticed for ICMP packets creating a DoS vector for these modems. The ICMP vulnerability is claimed to have been fixed by the v9 firmware series. Since then it has also been shown that UDP, RDP and in certain cases even TCP packets will have similar effects.
So, where do DNS lookups come into this?
When a local DNS server, for example one running on your router, is working in resolver mode it will recursively walk down from the root DNS server through a list of additional DNs servers to find the authoritative nameserver for the domain it is trying to look up. This process involves the exchange of a burst of small UDP packets. If repeated at a sufficiently high frequency this will exhaust most of the available resources in the Puma chipset and things will start to fall apart.
If the local DNS is operating in forwarder mode, it is simply asking an other DNS server to perform the address resolution and then send the result back. More importantly, it is doing it only once and there is no repetitive recursion. The result is significantly reduced UDP traffic.
This seems to work most of the time, but there is no guarantee the problem will not raise its ugly head again. If that happens, it probably will be necessary to fire up WireShark to pin down the cause.
Great post. But is there a fix for people who don\’t have a OPNsense router? For example I have the Virgin Media Hub in modem mode which is connected to my Asus RT-AC88U as the router.
I am not familiar with the Asus RT-AC88U, but there probably are settings to configure DNS lookups. Having said that, in your case it may well be something else, and not DNS lookups. The only way to find out would be to monitor the network traffic between router and modem, e.g. by using Wireshark. Also, the problem could simply be caused by traffic congestion on an oversubscribed VM network. Sorry I cannot be more helpful…
Thank you for your reply. I changed my DNS settings a long time ago to CloudFlare but that only made pages load up faster and did not affect my latency at all. However, the Forwarding Mode is what interests me as that seems what is bypassing the rubbish Puma 6 chipset of the VM Hub. Even with the Hub being in modem mode and my Asus router doing most of the legwork, it still seems that the Puma 6 chipset is handling the incoming traffic, which is a disaster. And as we all know Virgin will not allow you to use your own modem.
On top of that, yes it looks like the network in my area is oversubscribed. Looking at the BQM as well over the last couple of months it also seems the latency is timed too perfectly for peak hours. Every weekday it starts and ends on the same hour. I\’m just very dubious at this point with the VM network. Will most probably making a switch to BT Openreach as soon as it is available in my area.